決策樹的運作方式類似於人類在對於一件事情的決策方式,我們可以透過下方這張圖來理解決策樹是如何運作的。一開始,我們先看看今天是平日還是假日,如果是平日,接著就看心情好不好決定要不要出門;如果是假日就看天氣好不好決定要不要出門。
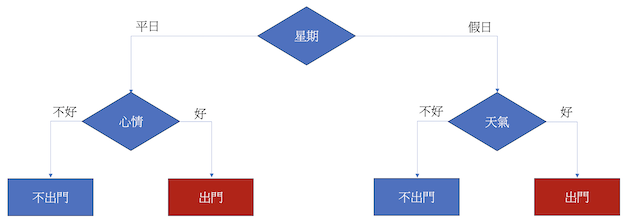
從上面的例子來看,是不是非常好理解呢?Decision Tree運作的方式就跟我們平常做決定時的思考方式非常類似,差別只在於當決策過程大時,人腦會很難反應過來,而電腦就可以清楚地根據規則來做出決定。
接下來我們要來理解決策樹用什麼方法去決定他的分類條件的,這邊介紹一種常用的分類依據—entropy(熵)。entropy是一種用來判斷這個分類依據好不好的方法,他的數值會介於0跟1之間,越接近0則代表這個分類分得越好、資料被分的統一,越接近1則代表分的越不好、資料種類繁雜。以下是entropy的計算公式,p代表成功(True)的機率、q代表失敗(False)的機率。
我們直接用一開始的例子來看看怎麼實際計算entropy的。假設一開始有十次決定出門和十次決定不出門的資料,如果我們用是假日還是平日去分類的話,有4個不出門和6個出門被分到平日、6個不出門和4個出門分到假日,那麼平日的entropy就會是 -(4 / 10) * log2(4 / 10) – (6 / 10) * log2(6 / 10) = 0.9852,而假日的entropy則是 –(6 / 10) * log2(6 / 10) - (4 / 10) * log2(4 / 10) = 0.9852。得出結果過後還要加權算出最後的entropy,所以用假日還是平日去分類的entropy為(10 / 20) * 0.9852 + (10 / 20) * 0.9852 = 0.9852。
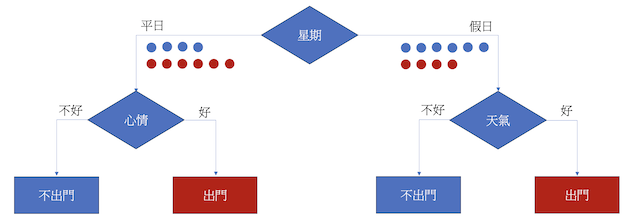
在上方的例子得到entropy過後,電腦會再以不同的分類依據去算出各自的entropy,最終以entropy最小的分類規則為最終的分類條件。


 iThome鐵人賽
iThome鐵人賽